grep(グレップ)とは、複数のテキストファイルにまたがって検索し、ヒットした文字列を一件一行としてリストしてくれる大変便利なツールです(ここではそういうことにしておいて下さい)。
サクラエディタに限らずテキストエディタには大抵grep機能が搭載されていますが、サクラエディタの場合こちらが欲している条件の1『正規表現に対応している』のは勿論、条件の3『検索にヒットした文字列のみを二次利用できる』のです。
正規表現の書き方については、『正規表現』とか『Perl5互換』で検索してその手の指南役サイトをあたって下さい。
注意すべきことは、サクラエディタはUnicodeに対応しているといっても文字列の内部処理をシフトJISで行っているので、シフトJISにない文字は表示も編集もできません。検索文字列に文字コード領域内全部の漢字(つまり一番最初の漢字=亜~一番最後の漢字=黑まで)を指定するときは、シフトJISのコード順で指定します。
#具体的にどんな順番で並んでいるかを簡単に調べるには、かな漢字変換の[IMEパッド]→[文字一覧]画面で、左上にある[Unicode]と[シフトJIS]を切り替えてみて下さい。
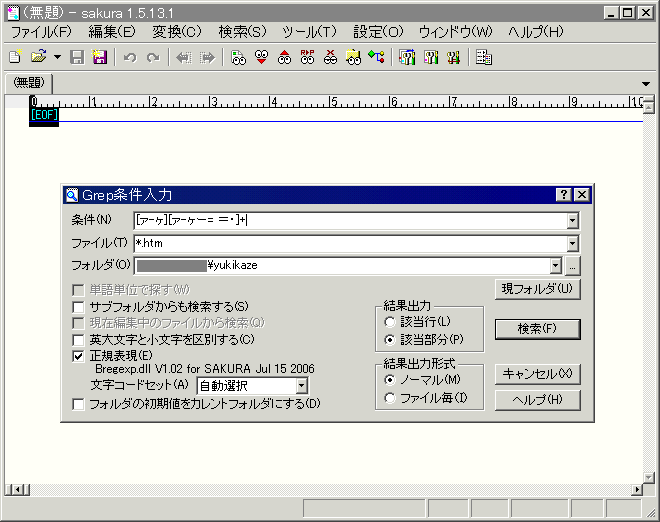
上記の検索条件を最低限説明すると、ひとつ目の[亜-黑]はシフトJISUnicodeでの『日本の漢字コード領域すべての漢字』一文字を表します(そういうことにしておいてください)。ふたつ目の[ 亜-黑]の中に半角スペースが入っているのは、例えば『深井 零』のように姓名の間にスペースが挟まっている場合に備えてのことです。『々』は漢字ではなく記号の範疇になるため追加してあります。末尾の半角『+』は直前の文字の繰り返しを表します。つまり“もしかすると間にスペースが入っているかもしれない二文字以上の漢字(と々)で構成された文字列”を検索対象とします。
カタカナを抽出する場合、二文字目以降に『ー(音引き)』『・(ナカグロ)』『==(半角と全角のイコール)』も検索するようにしてありますが、これは“カール・グスタフ”とか“クワイ=ガン・ジン”といった、本来ひとつながりの文字列として扱いたいものが“カール”と“グスタフ”の別々に文字列として扱われてしまうのを防ぐためです。
二文字以上の全角・半角の英数文字と半角の記号を抽出します。
正直なところ英単語ならスペルチェッカーを使った方が話が早そうなので、カタカナ抽出と組み合わせて『12.7ミリ』とかを検出できるようにすると便利かもしれません(やり方は自分で考えてね)。
実際の操作手順は以下の通りです。
※リンク先にカタカナ検索を行ったときの画面画像を用意しました。但し複数の状態の画面を合成したので、実際の状態とは異なっていることをお断りしておきます。
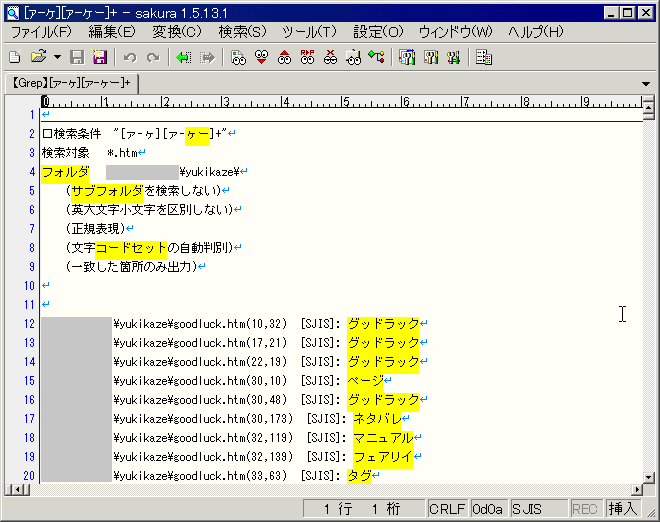
検索結果は以下のようになります。
C:\hoge\hoge.txt(1,11) [SJIS]: 賢作 C:\hoge\hoge.txt(2,15) [SJIS]: 弛緩
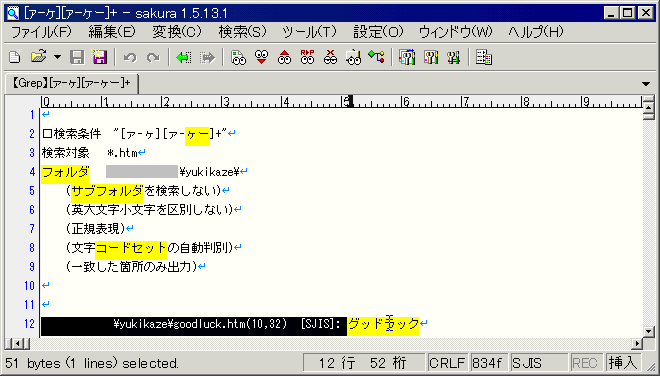
ヒットした文字列の前のファイルパスその他(画像だと黒い選択範囲部分)はこの場合不要な情報なので検索・置換で削除します。
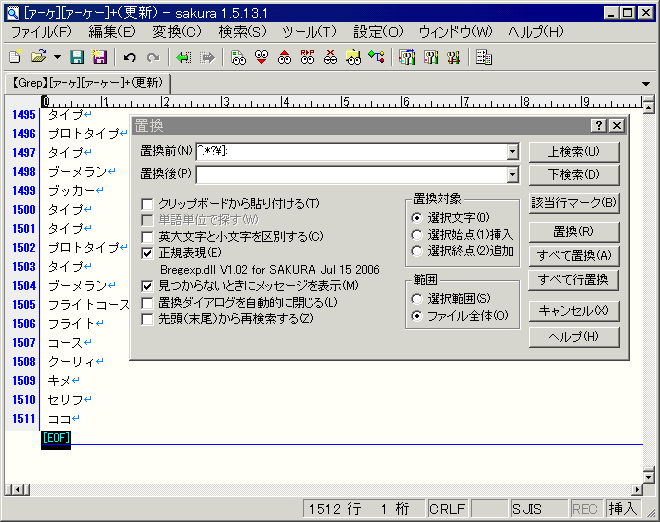
次いで抽出した文字列にソート(sort)をかけて順番に並べ直し、同じ文字列があれば複数行に渡って同じ内容が列挙されるので、今度は二行以上に重複した行を一行だけ残して削除(uniq)します。
サクラエディタはキーボードの入力履歴を保存して再利用できるキーボードマクロ機能があるので、上記のgrep終了後一連の操作を記録したマクロファイルを作ってみました。これを登録して実行すればほぼ一瞬でカタがつきます。
自動でらくらくとはいうものの、結局のところ最後の最後は肉眼でチェックということになりますし、元から間違って憶えていた場合に対しても無力ですが、それでも
『クーリィ』
『クーリー』
『クーリィー』
が上下に並んでいれば、まぁ見つけ出しやすいのではないでしょうか。
{kind=link}
{kind=link}
{kind=link}
{kind=link}